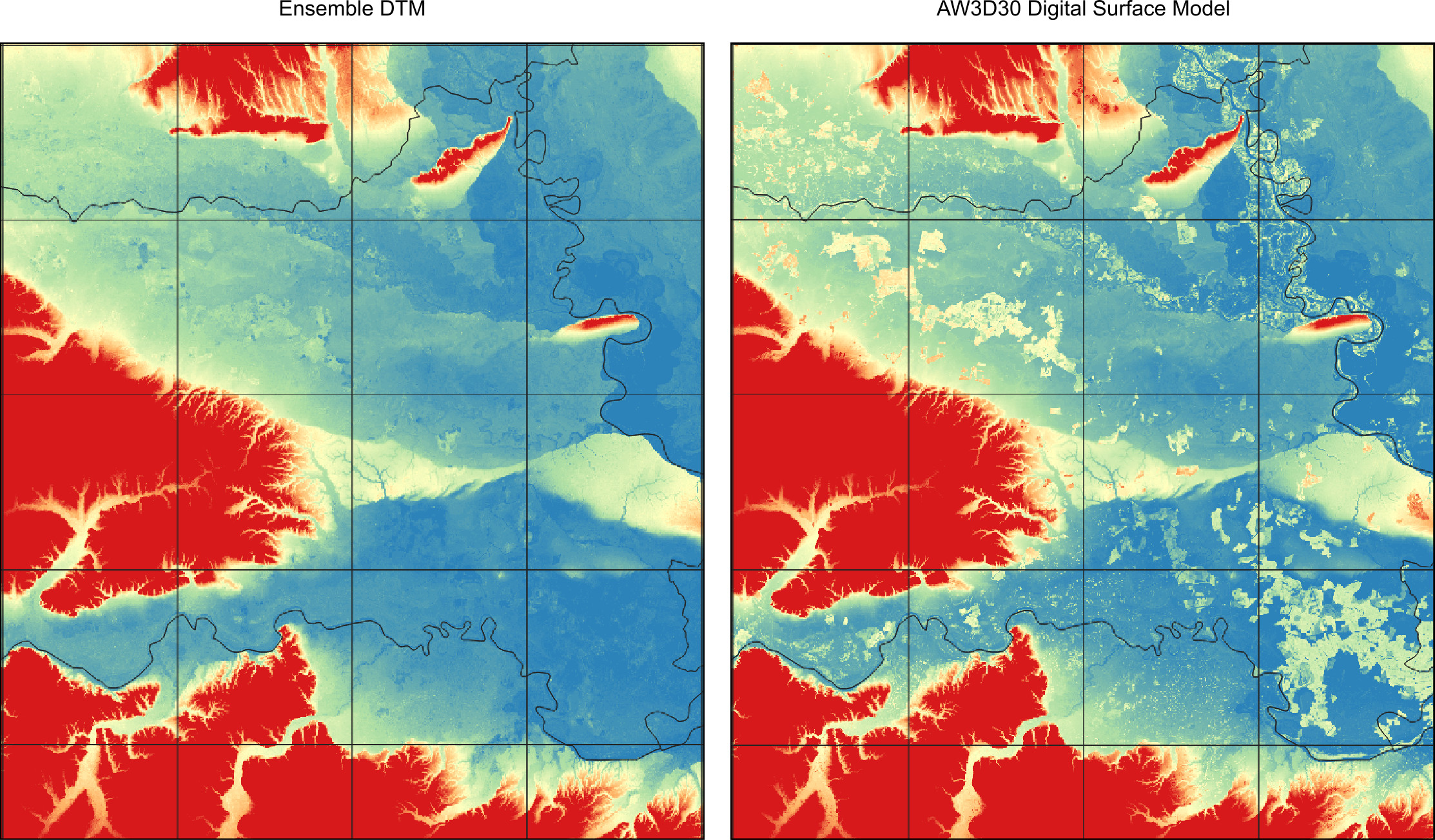
Prepared and maintained by: Tom Hengl (OpenGeoHub), Leandro Parente (OpenGeoHub), Josip Križan (MultiOne), Carmelo Bonannella (OpenGeoHub)
The Geo-harmonizer project requires an up-to-date terrain model of Continental Europe that can be used for land cover, vegetation and soil mapping. Currently at least three public global Digital Elevation Models exist that cover Europe and are available for spatial modeling:
- Digital Surface Model based on the USGS NASADEM,
- Digital Surface Model based on ALOS AW3D,
- Copernicus EU DEM based on the SRTM and ASTER DEMs,
- MERIT DEM (100-m) produced by Yamazaki et al. (2017),
- ESA’s Copernicus GLO-30,
This project obviously needs only a single model of relief, so a logical solution is to derive an Ensemble estimate of terrain height i.e. elevation of the bare earth or land surface.
Since 2018 several space-born missions have been collecting altitude / elevation data using precise and consistent instruments. This include:
- ICESat-2 points,
- GEDI Level2B points,
Because GEDI is newer mission and more focused on mapping vegetation, we have decided to use it as a reference, in this work, to train a model to predict the most probable terrain elevation. GEDI data can be obtained using the rGEDI package. We have downloaded GEDI Level2B data for whole world and then prepared an extract of points covering continental EU (about 28 million points with “elev.lowestmode” i.e. the estimate of the terrain height). GEDI unfortunately does not cover latitudes above 52°N (see below).
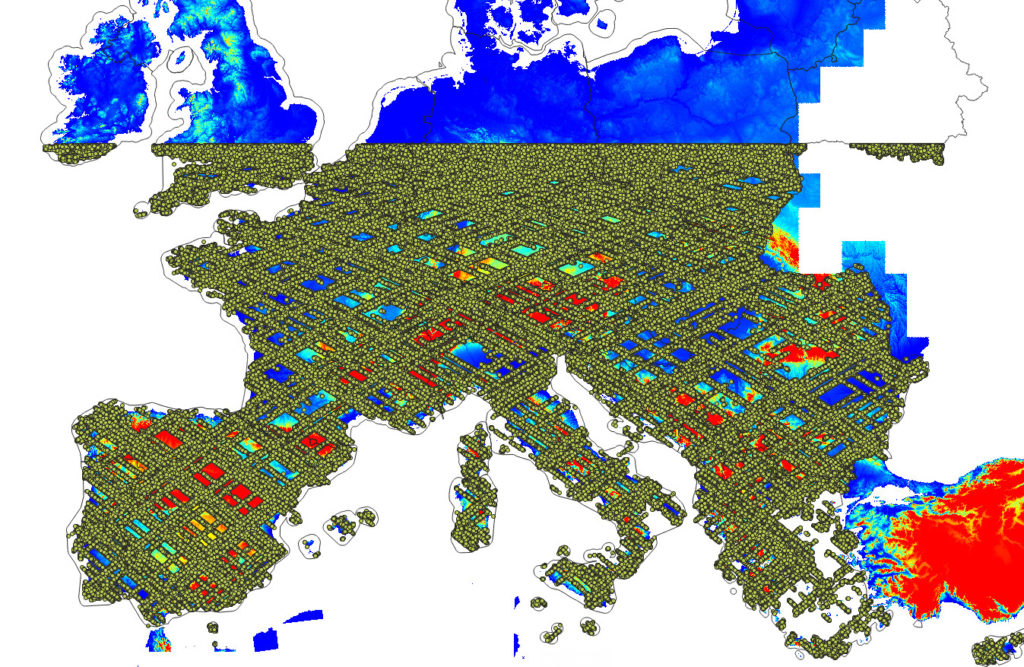
GEDI density training points Europe. Additional ICESat-2 points were added in the version v0.3.
The NASA DEM and ALSO AW3D are surface models hence they include canopy height and this represent a problem for deriving terrain model. UMD GLAD group has recently release a global canopy height map for 2019, also based on GEDI data. This data can be used help predict the terrain model with higher accuracy. There are however two limitations of the GEDI data set and these are: (1) limited coverage to 52 degrees north, (2) systematic clustering of points on the satellite path. These did not seem to cause problems in the modeling but should not be ignored.
In addition, Global Surface Water Explorer and Global Forest Change projects have release number of global products that contain information about the surface water probability and forest tree cover. In total we have prepared 9 auxiliary gridded layers at 30 m that we use to train a model to predict terrain. The summary ensemble model is hence:
m.elev = train_eml(t.var="elev_lowestmode",
pr.var = c("eu_AW3D_30m_f", "eu_GLO_30m_f", "eu_dem25m_", "eu_GlobalSurfaceWater_2016_30m_", "treecover2010_", "bare2010_", "treecover2000_", "eu_canopy_height_30m_"),
X=as.data.frame(ovT.df), out.dir="/data/EU_layers/modelsM/",
SL.library = c("regr.ranger", "regr.glmnet", "regr.cvglmnet", "regr.cubist"))
where t.var is the target variable, ovT.df is the regression matrix containing values of the GEDI points and result of spatial overlay with all layers, and SL.library contains the list of integrated learners used in the mlr package framework (mlr::makeStackedLearner) to estimate the ensemble model. Note that, for training the EML, we also use spatial blocks of 30×30 km to ensure that cross-validation protects from over-fitting due to spatial clustering. The summary result we get (note: we randomly subset to max 7 million points for the purpose computational efficiency i.e. to avoid memory problems) show:
Variable: elev_lowestmode.f
R-square: 1
Fitted values sd: 333
RMSE: 6.54
Ensemble model:
Call:
stats::lm(formula = f, data = d)
Residuals:
Min 1Q Median 3Q Max
-118.788 -0.871 0.569 1.956 165.119
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.198402 0.003045 -65.15 <2e-16 ***
regr.ranger 0.452543 0.001117 405.04 <2e-16 ***
regr.cubist 0.527011 0.001516 347.61 <2e-16 ***
regr.glm 0.020033 0.001217 16.47 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.544 on 9588231 degrees of freedom
Multiple R-squared: 0.9996, Adjusted R-squared: 0.9996
F-statistic: 8.29e+09 on 3 and 9588231 DF, p-value: < 2.2e-16Which indicates that the elevation errors are in average (2/3rd of pixels) between ±2-3 m. This in general demonstrates that combining multiple Digital Surface Models with canopy heights and forest density maps can be used to significantly improve (absolute) accuracy of e.g. SRTM DEM (currently estimated to be around ±12 m).
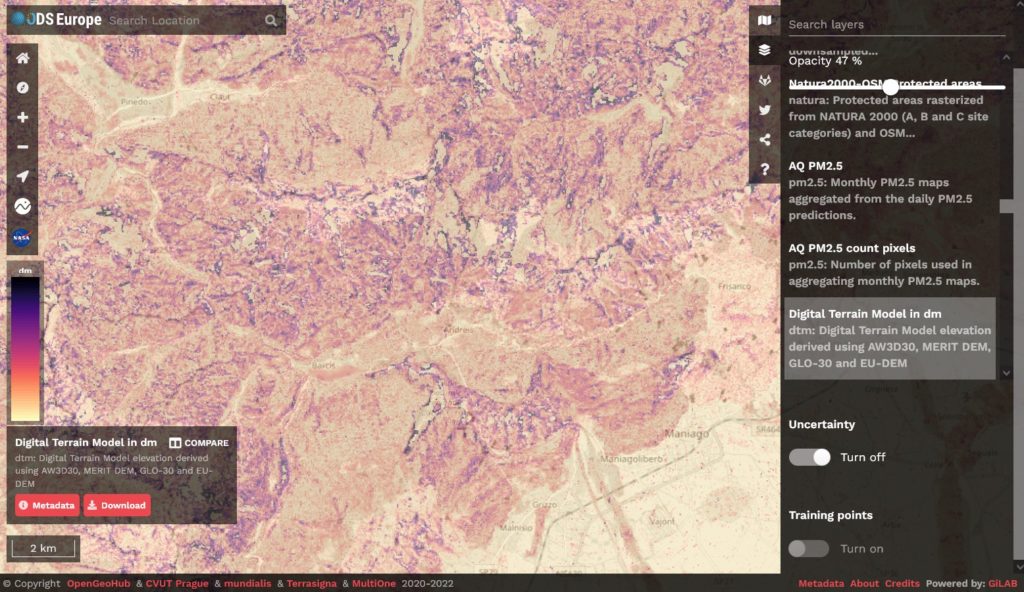
Prediction errors for elevation (in dm). Shown in the Open Data Science Europe Viewer.
From the five DSM/DTM original data sources (MERITDEM, AW3D30, GLO-30, EU DEM, GLAD canopy height) it appears that MERIT DEM is the most important for producing DTM (at least for the European continent):
Variable importance:
variable importance
4 eu_MERITv1.0.1_30m_ 430641370770
1 eu_AW3Dv2012_30m_ 291483345389
2 eu_GLO30_30m_ 201517488587
3 eu_dem25m_ 132742500162
9 eu_canopy_height_30m_ 5148617173
7 bare2010_ 2087304901
8 treecover2000_ 1761597272
6 treecover2010_ 141670217AW3Dv2012 and GLO-30 come on the second place, with about equal importance.
The final predictions and the training points can be downloaded as Cloud Optimized GeoTIFFS and the code used to prepare data, fit models and generate predictions can be accessed here. Note that the initial results are promising, but there are still number of issue that we plan to resolve:
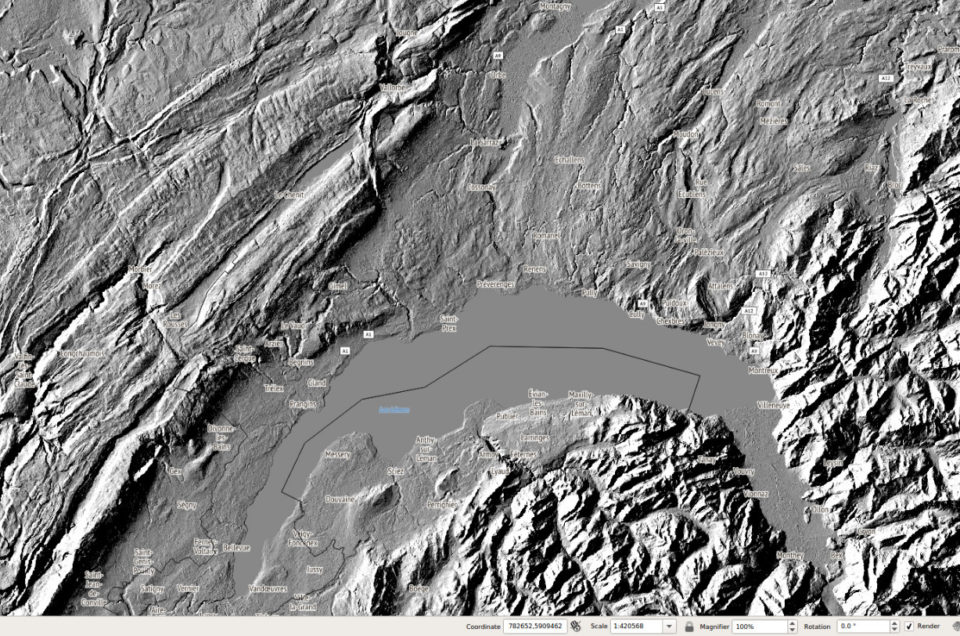
- In many places canopy height is still visible on the hillshading images, indicating that even after using the canopy height, the true terrain elevation in forests is over-estimated,
- Additional filtering is needed to remove also human built objects in urban areas.
- The EML-based Digital Terrain Model has not be hydrologically corrected / pre-processed, hence additional processing is needed before this DTM could be used for spatial modeling,
Update 3-February 2021:
- GLO-30 DEM and MERIT DEM (downscaled to 30-m resolution) have been added to the list of input DEM,
- The variable importance based on random forest algorithm indicates that MERIT DEM is, in fact, most important for producing DTM, this is most likely because the Yamazaki et al. (2017) have successfully removed most of the canopy problems, so that even though it is only a coarse resolution DTM (100-m), it matches the best GEDI points,